欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
- 基本数据类型
- 复杂数据类型
- 内部表和外部表
- 分区表
- 分桶
- HiveQL基础
- 内置函数
- Sqoop
- 基础UDF
- 用户自定义聚合函数(UDAF)
- UDTF
本篇概览
本文是《hive学习笔记》的第五篇,前文学习了分区表,很容易发现分区表的问题:
- 分区字段的每个值都会创建一个文件夹,值越多文件夹越多;
- 不合理的分区会导致有的文件夹下数据过多,有的过少;
此时可以考虑分桶的方式来分解数据集,分桶原理可以参考MR中的HashPartitioner,将指定字段的值做hash后,根据桶的数量确定该记录放在哪个桶中,另外,在join查询和数据取样时,分桶都能提升查询效率;
- 接下来开始实战;
配置
- 执行以下设置,使得hive根据桶的数量自动调整上一轮reducers数量:
set hive.enforce.bucketing = true;- 如果不执行上述设置,您需要自行设置mapred.reduce.tasks参数,以控制reducers数量,本文咱们配置为hive自动调整;
准备数据
接下来先准备外部表t13,往里面添加一些数据,将t13作为后面分桶表的数据源:
- 表名t13,只有四个字段:
create external table t13 (name string, age int, province string, city string) row format delimited fields terminated by ',' location '/data/external_t13';- 创建名为013.txt的文件,内容如下:
tom,11,guangdong,guangzhoujerry,12,guangdong,shenzhentony,13,shanxi,xianjohn,14,shanxi,hanzhong- 将013.txt中的四条记录载入t13:
load data local inpath '/home/hadoop/temp/202010/25/013.txt' into table t13;分桶
- 创建表t14,指定字段分桶,桶数量为16:
create table t14 (name string, age int, province string, city string) clustered by (province, city) into 16 bucketsrow format delimited fields terminated by ',';- 从t13导入数据,注意语法是from t13开始,要用overwrite关键字:
from t13insert overwrite table t14 select name, age, province, city;- 导入过程如下图所示,可见reducer数量已被自动调整为桶数量:
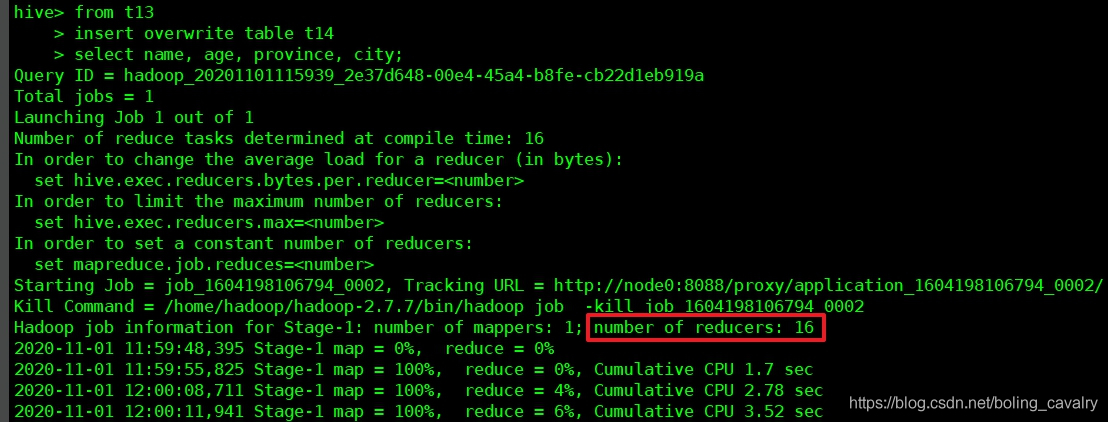
- 导入后,查看hdfs,可见被分为16个文件,(和分区对比一下,分区是不同的文件夹):
UDTF本篇概览本文是《hive学习笔记》的第五篇<span id='KeyList'><br /><a href='https://www.ikjzd.com/w/2133'>farfetch</a>:https://www.ikjzd.com/w/2133<br /><a href='https://www.ikjzd.com/articles/11956'>一份来自eBay卖家的控诉:eBay竟然隐藏我的拍卖清单!!</a>:https://www.ikjzd.com/articles/11956<br /><a href='https://www.ikjzd.com/articles/11962'>曝!又一品牌起诉侵权,多位卖家惨遭巨额罚款!</a>:https://www.ikjzd.com/articles/11962<br /><a href='https://www.ikjzd.com/articles/11964'>西班牙人爱上阿里速卖通,双11、黑五包裹收不停!</a>:https://www.ikjzd.com/articles/11964<br /><a href='https://www.ikjzd.com/articles/11970'>俄罗斯科技巨头推出两个电商平台</a>:https://www.ikjzd.com/articles/11970<br /><a href='http://lady.shaoqun.com/m/a/247805.html'>老师洗澡时让我进去摸她 老师胸好大下面紧舒服</a>:http://lady.shaoqun.com/m/a/247805.html<br /><a href='http://www.30bags.com/m/a/249901.html'>把班主任玩到怀孕 老师奶头好大,下面好多水水</a>:http://www.30bags.com/m/a/249901.html<br /><a href='http://www.30bags.com/m/a/249765.html'>女班主任在我胯间喘息 掀开超短裙老师裙子挺进去</a>:http://www.30bags.com/m/a/249765.html<br /><a href='http://www.30bags.com/a/470636.html'>白河峡谷漂流怎么样,好玩吗?</a>:http://www.30bags.com/a/470636.html<br /><a href='http://lady.shaoqun.com/a/400663.html'>晚上下班婆婆把我锁在外面,半夜在公园长椅上被陌生人侵犯</a>:http://lady.shaoqun.com/a/400663.html<br /><a href='http://lady.shaoqun.com/a/400664.html'>女生在公园锻炼,却在大白天被陌生男人猥亵!</a>:http://lady.shaoqun.com/a/400664.html<br /><a href='http://lady.shaoqun.com/a/400666.html'>学会这样做,轻松)
No comments:
Post a Comment