一、容器之List集合
List集合体系应该是日常开发中最常用的API,而且通常是作为面试压轴问题(JVM、集合、并发),集合这块代码的整体设计也是融合很多编程思想,对于程序员来说具有很高的参考和借鉴价值。
基本要点
- 基础:元素增查删、容器信息;
- 进阶:存储结构、容量管理;
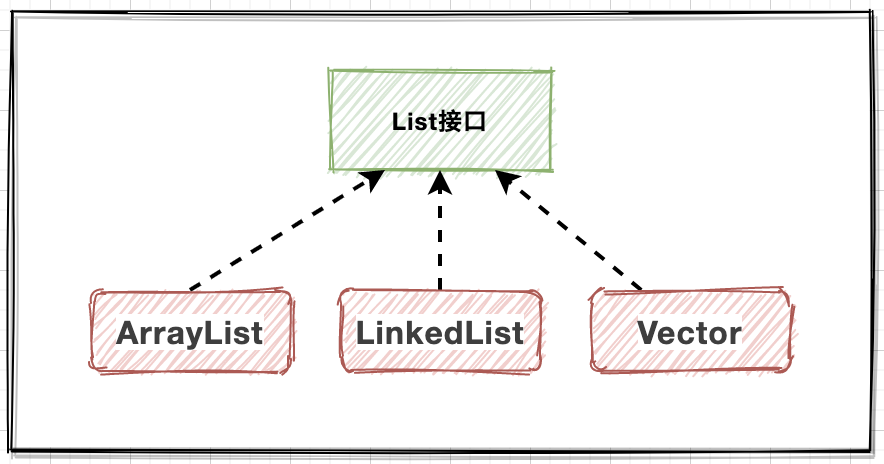
API体系
- ArrayList:维护数组实现,查询快;
- Vector:维护数组实现,线程安全;
- LinkedList:维护链表实现,增删快;
核心特性包括:初始化与加载,元素管理,自动扩容,数组和链表两种数据结构。Vector底层基于ArrayList实现的线程安全操作,而ArrayList与LinkedList属于非线程安全操作,自然效率相比Vector会高,这个是通过源码阅读可以发现的特点。
二、ArrayList详解
1、数组特点
ArrayList就是集合体系中List接口的具体实现类,底层维护Object数组来进行装载和管理数据:
private static final Object[] EMPTY_ELEMENTDATA = {};提到数组结构,潜意识的就是基于元素对应的索引查询,所以速度快,如果删除元素,可能会导致大量元素移动,所以相对于LinkedList效率较低。
数组存储的机制:
数组属于是紧凑连续型存储,通过下标索引可以随机访问并快速找到对应元素,因为有预先开辟内存空间的机制,所以相对节约存储空间,如果数组一旦需要扩容,则重新开辟一块更大的内存空间,再把数据全部复制过去,效率会非常的低下。
2、构造方法
这里主要看两个构造方法:
无参构造器:初始化ArrayList,声明一个空数组。
public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}有参构造器:传入容量参数大于0,则设置数组的长度。
public ArrayList(int initialCapacity) { if (initialCapacity > 0) { this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { this.elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity); }}如果没通过构造方法指定数组长度,则采用默认数组长度,在添加元素的操作中会设置数组容量。
private static final int DEFAULT_CAPACITY = 10;3、装载数据
通过上面的分析,可以知道数组是有容量限制的,但是ArrayList却可以一直装载元素,当然也是有边界值的,只是通常不会装载那么多元素:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;超过这个限制会抛出内存溢出的错误。
装载元素:会判断容量是否足够;
public boolean add(E e) { ensureCapacityInternal(size + 1); elementData[size++] = e; return true;}当容量不够时,会进行扩容操作,这里贴量化关键源码:
private void grow(int minCapacity) { int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); elementData = Arrays.copyOf(elementData, newCapacity);}机制:计算新容量(newCapacity=15),拷贝一个新数组,设置容量为newCapacity。
指定位置添加:这个方法很少使用到,同样看两行关键代码;
public void add(int index, E element) { ensureCapacityInternal(size + 1); System.arraycopy(elementData, index,elementData,index+1,size-index); elementData[index] = element; size++;}机制:判断数组容量,然后就是很直接的一个数组拷贝操作,简单来个图解:
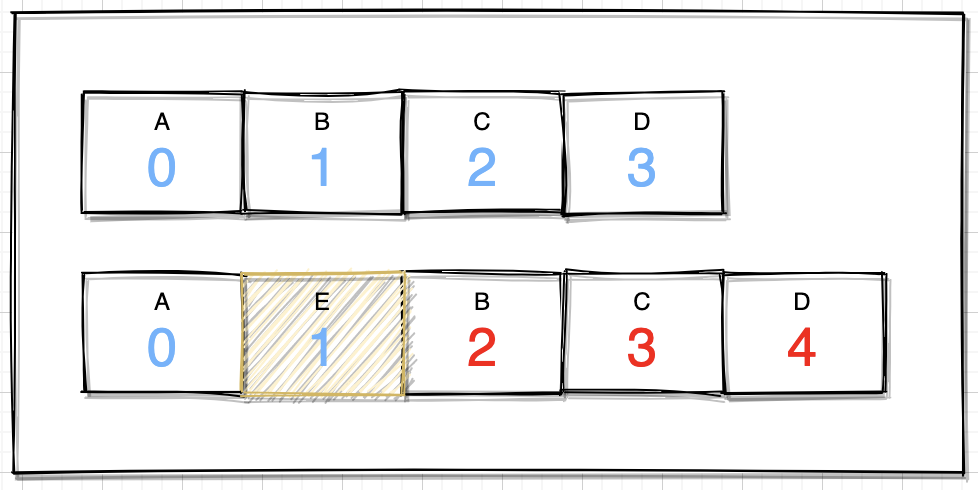
如上图,假设在index=1位置放入元素E,按照如下过程运行:
- 获取数组index到结束位置的长度;
- 拷贝到index+1的位置;
- 原来index位置,放入element元素;
这个过程就好比排队,如果在首位插入一位,即后面的全部后退一位,效率自然低下,当然这里也并不是绝对的,如果移动的数组长度够小,或者一直在末尾添加,效率的影响自然就降低很多。
4、移除数据
上面看的数据装载,那与之相反的逻辑再看一下,依旧看几行关键源码:
public E remove(int index) { E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(elementData, index+1, elementData, index, numMoved); } elementData[--size] = null; return oldValue;}机制:从逻辑上看,与添加元素的机制差不多,即把添加位置之后的元素拷贝到index开始的位置,这个逻辑在排队中好比前面离开一位,后面的队列整体都前进一位。
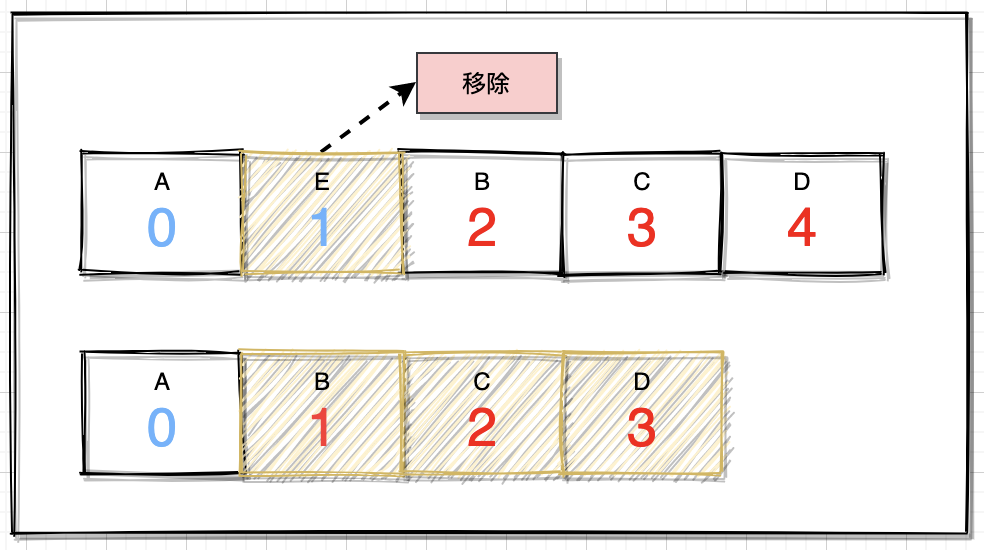
其效率问题也是一样,如果移除集合的首位元素,后面所有元素都要移动,移除元素的位置越靠后,效率影响就相对降低。
5、容量与数量
在集合的源码中,有两个关键字段需要明确一下:
- capacity:集合的容量,装载能力;
- size:容器中装载元素的个数;
通常容器大小获取的是size,即装载元素个数,不断装载元素触发扩容机制,capacity容量才会改变。
三、LinkedList详解
1、链表结构特点
链表结构存储在物理单元上非连续、非顺序,节点元素间的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,节点可以在运行时动态生成,节点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
特点描述
- 物理存储上是无序且不连续的;
- 链表是由多个节点以链式结构组成;
- 逻辑层面上看形成一个有序的链路结构;
- 首节点没有指向上个节点的地址;
- 尾节点没有指向下个节点的地址;
链表结构解决数组存储需要预先知道元素个数的缺陷,可以充分利用内存空间,实现灵活的内存动态管理。
2、LinkedList结构
LinkedList底层数据存储结构正是基于链表实现,首先看下节点的描述:
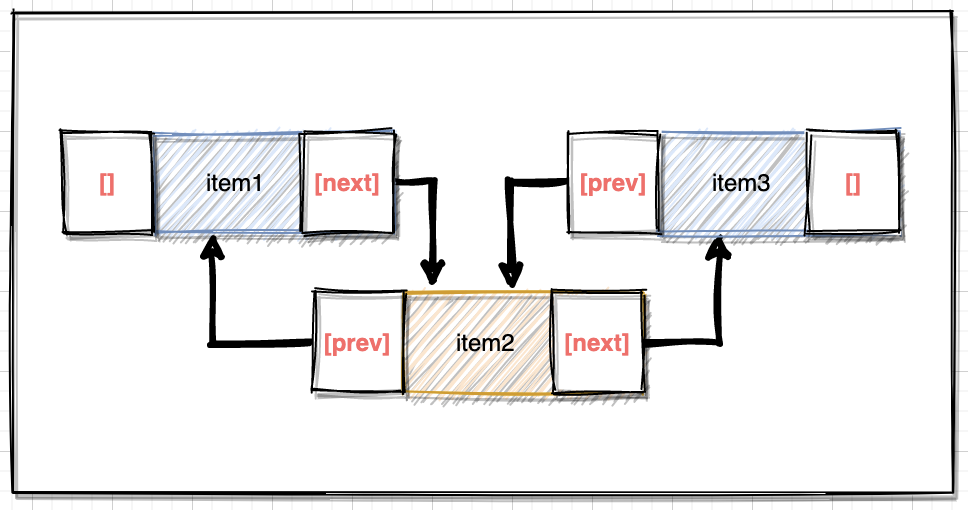
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; }}在LinkedList中定义静态类Node描述节点的结构:元素、前后指针。在LinkedList类中定义三个核心变量:
transient int size = 0;transient Node<E> first;transient Node<E> last;即大小,首位节点,关于这个三个变量的描述在源码的注释上已经写的非常清楚了:
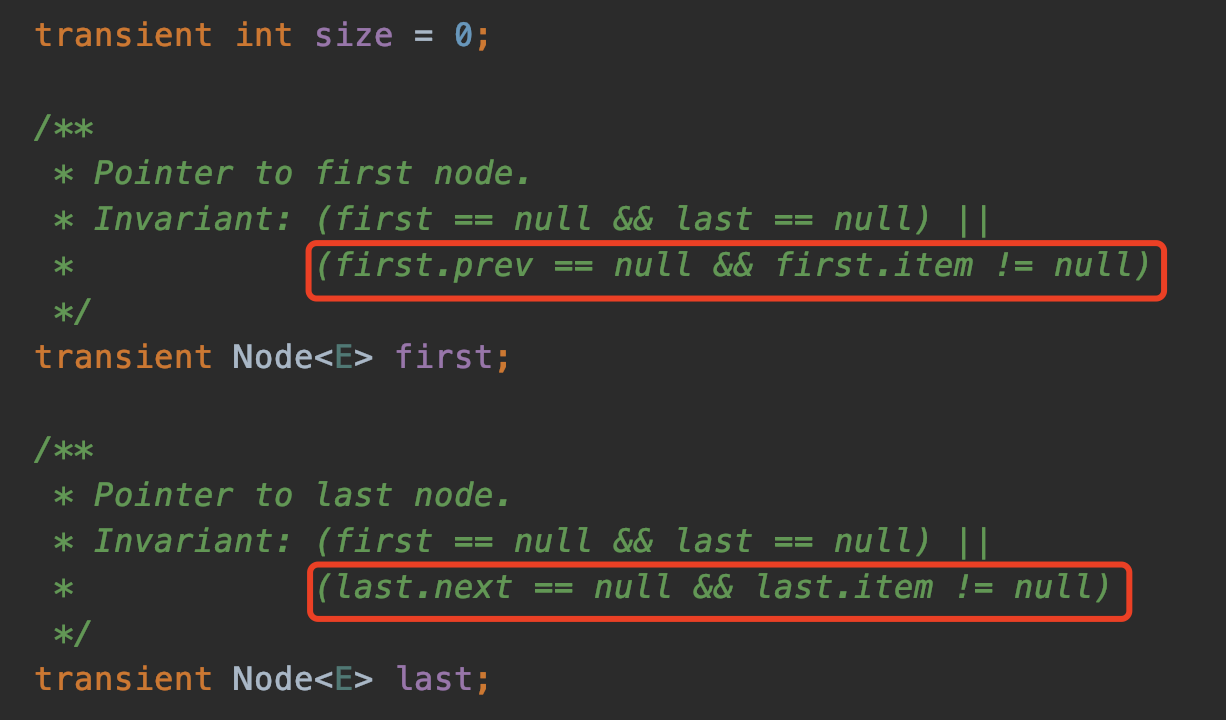
首节点上个节点为null,尾节点下个节点为null,并且item不为null。
3、元素管理
LinkedList一大特点即元素增加和删除的效率高,根据链表的结构特点来看源码。
添加元素
通过源码可以看到,添加元素时实际调用的是该方法,把新添加的元素放在原链表最后一位:
void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++;}结合Node类的构造方法,实际的操作如下图:
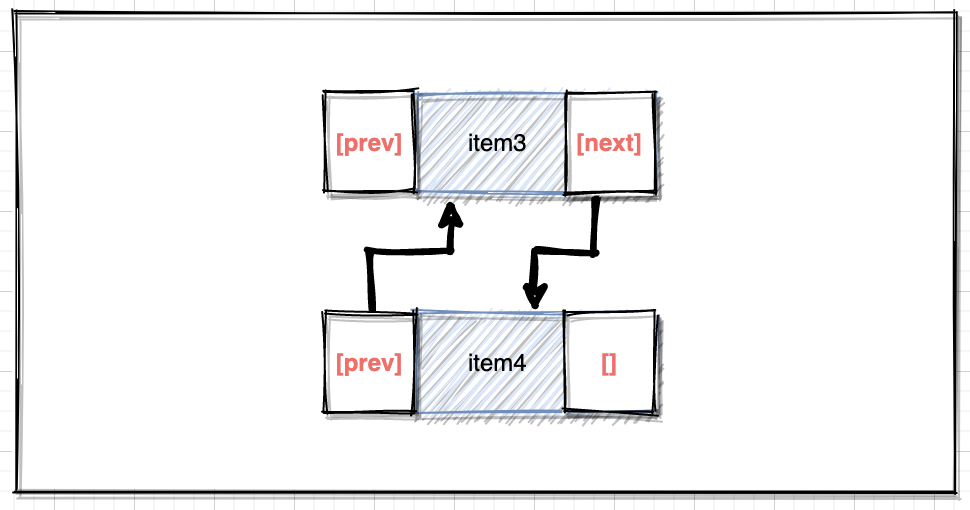
核心的逻辑即:新的尾节点和旧的尾节点构建指针关系,并处理首位节点变量。
删除元素
删除元素可以根据元素对象或者元素index删除,最后核心都是执行unlink方法:
E unlink(Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element;}与添加元素核心逻辑相似,也是一个重新构建节点指针的过程:

- 两个if判断是否删除的是首位节点;
- 删除节点的上个节点的next指向删除节点的next节点;
- 删除节点的下个节点的prev指向删除节点的prev节点;
通过增删方法的源码分析,可以看到LinkedList对元素的增删并不会涉及大规模的元素移动,影响的节点非常少,效率自然相对ArrayList高很多。
4、查询方法
基于链表结构存储而非数组,对元素查询的效率会有很大影响,先看源码:
public E get(int index) { checkElementIndex(index); return node(index).item;}Node<E> node(int index) { if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; }}这段源码结合LinkedList结构看,真的是极具策略性:
- 首先是对index的合法性校验;
- 然后判断index在链表的上半段还是下半段;
- 如果在链表上半段:从first节点顺序遍历;
- 如果在链表下半段:从last节点倒序遍历;
通过上面的源码可以看到,查询LinkedList中靠中间位置的元素,需要执行的遍历的次数越多,效率也就越低,所以LinkedList相对更适合查询首位元素。
四、源代码地址
GitHub·地址https://github.com/cicadasmile/java-base-parentGitEE·地址https://gitee.com/cicadasmile/java-base-parent
阅读标签
【Java基础】【设计模式】【结构与算法】【Linux系统】【数据库】
【分布式架构】【微服务】【大数据组件】【SpringBoot进阶】【Spring&Boot基础】
【数据分析】【技术导图】【 职场】
原文转载:http://www.shaoqun.com/a/747782.html
敦煌网:https://www.ikjzd.com/w/189
stadium:https://www.ikjzd.com/w/2729
List集合体系应该是日常开发中最常用的API,而且通常是作为面试压轴问题(JVM、集合、并发),集合这块代码的整体设计也是融合很多编程思想,对于程序员来说具有很高的参考和借鉴价值。一、容器之List集合List集合体系应该是日常开发中最常用的API,而且通常是作为面试压轴问题(JVM、集合、并发),集合这块代码的整体设计也是融合很多编程思想,对于程序员来说具有很高的参考和借鉴价值。基本要点基础:
shopyy:https://www.ikjzd.com/w/1661
c88是什么:https://www.ikjzd.com/w/1017
转运四方:https://www.ikjzd.com/w/1342
青春正当时情难自抑 口述我和女友的第一次亲密经历:http://lady.shaoqun.com/a/269868.html
夸克:https://www.ikjzd.com/w/1237
亚马逊与联邦快递"七夕分手":没有你我照样过得好!:https://www.ikjzd.com/home/103912
No comments:
Post a Comment