redis5之前集群搭建需要ruby环境,redis5之后就不需要了,只用redis-cli就可以创建集群了,本文redis版本:5.0.4
1.前期回顾
前面说了redis的主从复制可以保证数据容灾,就是主节点坏了,从节点中也保存着完整数据,不会造成数据丢失的情况;
然后又说了哨兵模式(sentinel),这个是在主从复制的基础上增强了一下,当主节点坏了,从节点中就会选举出来一个当作主节点,继续对外提供服务,而不需要人为的去操作,这叫做保证自动故障转移;
注意,哨兵的个数之前只配置了一个,其实可以配置多个,防止一个哨兵由于网络延迟等原因误判了;多个哨兵的时候超过半数的哨兵觉得主节点挂了那么就是主节点挂了,才会选举新的主节点;
哨兵模式下,使用springboot去连接redis的时候,连接的哨兵节点哦!因为此时主节点的ip是不确定的,有兴趣的可以自己测试;
2. redis单机版的缺陷
哨兵模式下,其实就可以适用于绝大多数公司的场景了,毕竟也没有那么多的用户
但是对于比较大的公司,用户数量贼多,然后并发量贼高,然后redis主节点只有一个,一下子就能将redis主节点打趴下了,然后哨兵重新推选新的主节点刚刚站起来,然后又一下子被打趴下了,不断的重复直至所有的redis节点都被打趴下了,最终所有请求都来到数据库,数据库也挂了....这也就是单节点并发压力的问题
而且只有单节点的话,redis持久化数据越来越多,直至最后持久化了TB级别的数据,其实是比较夸张的
所以我们更希望能有多个redis主节点服务器可以提供服务,每个主节点有从节点,而且还有有类似之前说的哨兵机制,那么持久化的数据能大概均分到各个服务器,而且可用性也有,单节点并发和磁盘压力也会大大的缓解
3 redis集群(cluster)说明
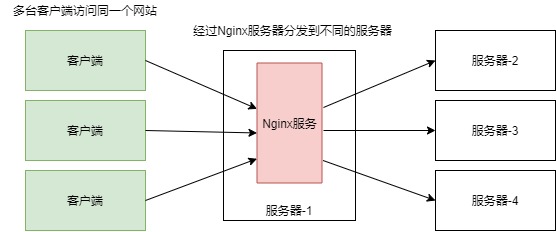
集群就类似下面这个图,集群中三个节点提供服务,三个节点都是主节点,同时三个节点都有从节点;
在集群模式下,主从节点自动的会有哨兵功能,即主节点挂了,从节点就会顶上;
下面的这种,redis持久化的数据可以大概的平均分成三份,分别存到每个节点中,所以,每个节点中存的数据是不一样的!!!
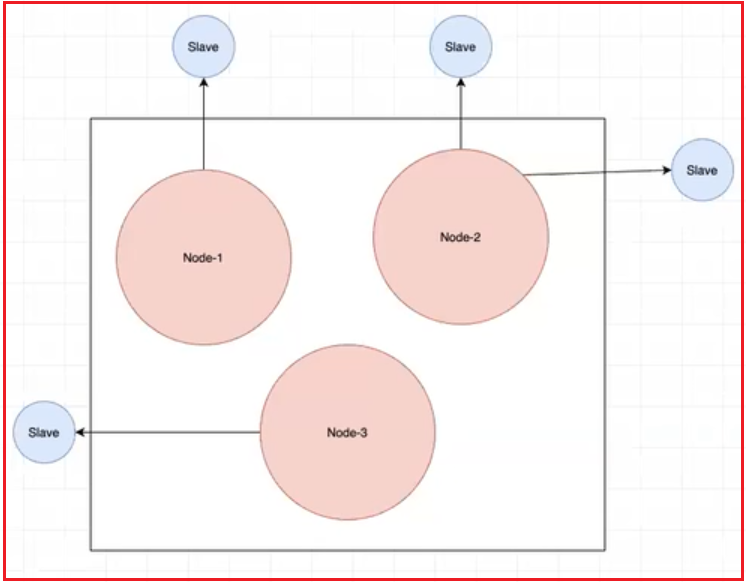
那么问题来了,一个集群中有那么多节点,我们如果要向里面存数据,那么怎么选择节点呢? 只有先选择了节点然后才能往这个节点中存入数据
例如set a 1,那么应该怎么向集群中存呢?
原理:类似于java中的hashmap,如果我有一个容量为16383的数组,分成三份,上面节点node-1 中管理的是0-5461的位置,node-2管理的是5462-10922的位置,然后node-3管理的是10923-16383的位置
然后a首先经过hash再对16383取余,得到的结果肯定是在0-16383之间的某个数字(在redis中就叫做CRC16算法),然后根据这个结果所在的位置就能确定放在哪个节点了
比如上面的set a 1 ,假设a经过CRC16算法得到的结果是7000,那就肯定丢到node-2里面去了,还是比较容易的,并且相同的键,经过CRC16算法,每次都是一样的,所以当使用get a 的时候,a经过CRC16之后,结果也是7000,也就到node-2中去取数据了
这实现了存的时候在哪个节点存,取得时候肯定就在那个节点去取;
4 redis在linux中简单使用
之前单机版都是windows中配置的,现在我们在linux中玩一下
4.1 安装redis源码
redis中文网 根据提示下载redis源码,我把安装命令放在下面,注意下载你想要的版本;
#下载,解压,编译:wget >.tar.gztar xzf redis-5.0.4.tar.gzcd redis-5.0.4make#二进制文件是编译完成后在src目录下. 运行如下:src/redis-server#你能使用Redis的内置客户端进行进行redis代码的编写:$ src/redis-cliredis> set foo barOKredis> get foo"bar"
你在执行make的时候应该会出错,因为redis是c语言写的,所以需要有c语言的编译环境,使用命令:yum install -y gcc
然后进入解压目录执行: make MALLOC=libc
继续在解压目录下执行:make install PREFIX=/usr/local/redis /usr/local/redis这个目录表示你的redis需要安装的位置,自己定义,后续的启动redis就是在/usr/local/redis/bin
进入刚刚redis的安装目录,执行命令:./redis-server
可以发现使用linux安装其实比较麻烦,而且如果你的运气不好,在使用yum安装gcc的时候也会有些奇葩的问题,慢慢踩坑吧!
4.2 启动redis哨兵
在前面我们安装了redis的源码包和编译后的redis,我们还需要redis服务端启动时候的配置文件,在源码包下,我们需要复制到编译后的redis目录下:cp /usr/local/java/redis/redis-5.0.4/redis.conf /usr/local/redis/bin 这个命令的前一个目录需要改成你自己的redis源码包的目录
由于我的redis版本比较新,所以redis编译后的包中有redis-sentinel文件,就不需要去源码包复制了(假设你的本目录没有这个redis-sentinel文件,你就需要去源码包中的src目录下将这个文件redis-sentinel给复制过来)
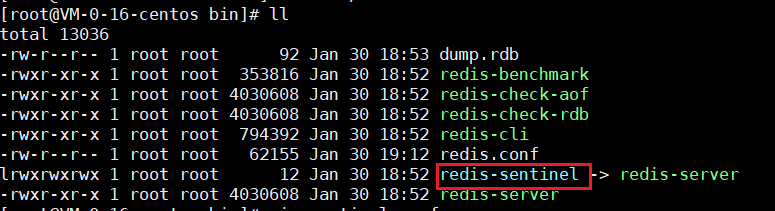
我们在当前bin目录下新建一个sentinel.conf配置文件,加入下面一行
sentinel monitor mymaster 127.0.0.1 6379 1
配置完毕,启动redis服务端:./redis-server ./redis.conf
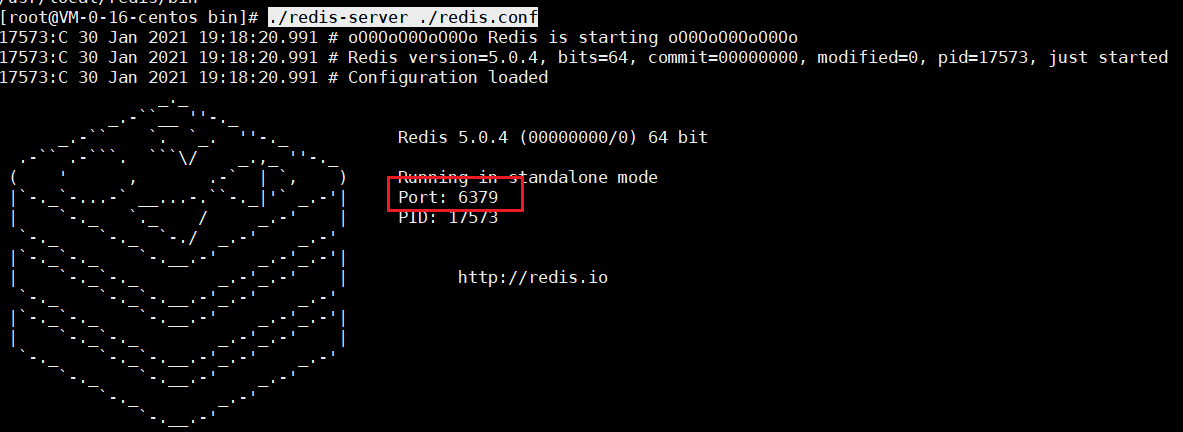
启动哨兵节点:./redis-sentinel ./sentinel.conf
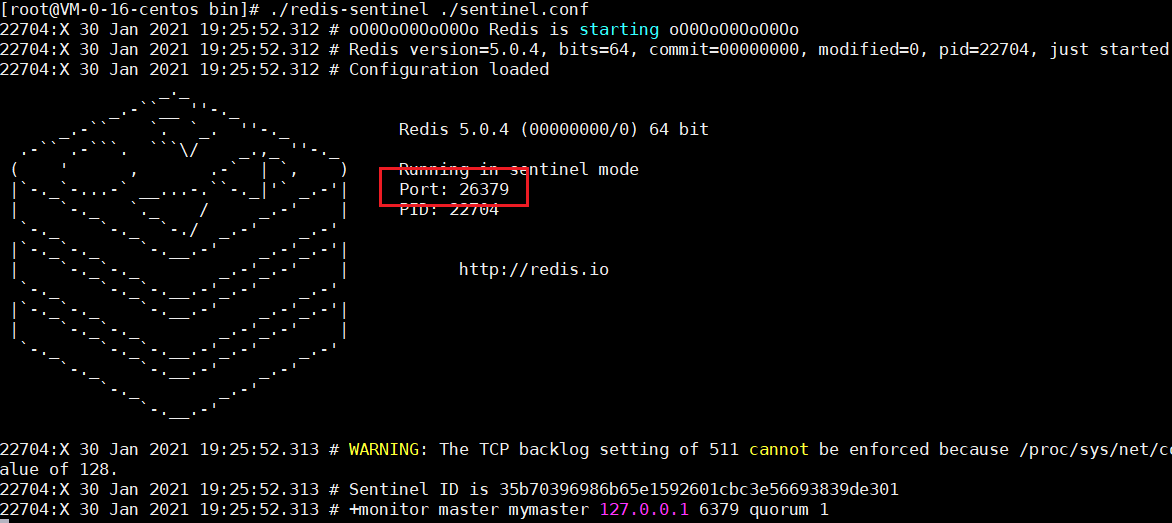
到这里,说明我们redis配置很ok,当然你也可以自己配置一个从节点,跟window版本是一样的,自己可以测试一下
5 redis集群搭建
5.1 提前须知
集群中的主从节点自带哨兵功能,而且主节点必须是奇数,最低需要三个主节点
我这里给每个主节点都配置一个从节点,三主三从,一共6个节点
我们设置5000,6000,7000为三个主节点,5001,6001,7001为三个从节点,注意,我们在集群中不能手动指定主节点和哪个从节点配对,这是随机的!我们只能指定主节点
5.2 redis.conf配置文件修改
复制6份redis.conf配置文件,然后修改下面个地方:
port 6379 //redis服务端的端口bind 0.0.0.0 //开启远程连接
daemonize yes //这里表示redis服务端以守护进行开启,也就是开启redis的时候,是在后台运行的
dbfilename dump.rdb //rdb持久化文件名需要修改
appendfilename "appendonly.aof" //aof持久化文件名需要修改
appendonly yes //集群模式必须开启aof持久化
dir . //持久化文件存放的目录
cluster-enabled yes //开启集群模式cluster-config-file nodes-port.conf //集群节点配置文件cluster-node-timeout 5000 //集群节点超时时间,单位毫秒
改完之后的文件放入下面的各自对应的目录中:
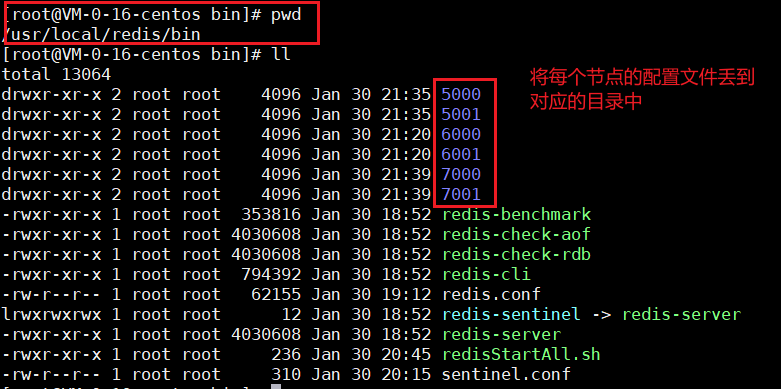
我们以5000端口为例,修改上面的几条,其他的配置文件根据各自的端口进行修改:
port 5000bind 0.0.0.0daemonize yes dbfilename dump5000.rdb appendfilename "appendonly5000.aof" appendonly yes
dir ./5000
cluster-enabled yes cluster-config-file nodes-5000.conf cluster-node-timeout 5000
改了好半天,终于改完了6个配置文件,然后在bin目录下编写一个启动所有节点的脚本: vim redisStartAll.sh
#! /bin/bash./redis-server ./5000/redis5000.conf./redis-server ./5001/redis5001.conf./redis-server ./6000/redis6000.conf./redis-server ./6001/redis6001.conf./redis-server ./7000/redis7000.conf./redis-server ./7001/redis7001.conf
给启动脚本添加可执行权限: chmod +x redisStartAll.sh
想要启动所有redis节点,在bin目录下直接执行: sh ./redisStartAll.sh

5.3 创建集群
我们将所有的节点启动完毕之后,虽然说都是节点,但都是各自隔离的,没有什么联系,我们需要将这些节点设置一下;(还是强调一下,redis5.x版本的集群模式不需要ruby环境,直接使用本地的reids-cli就行了)
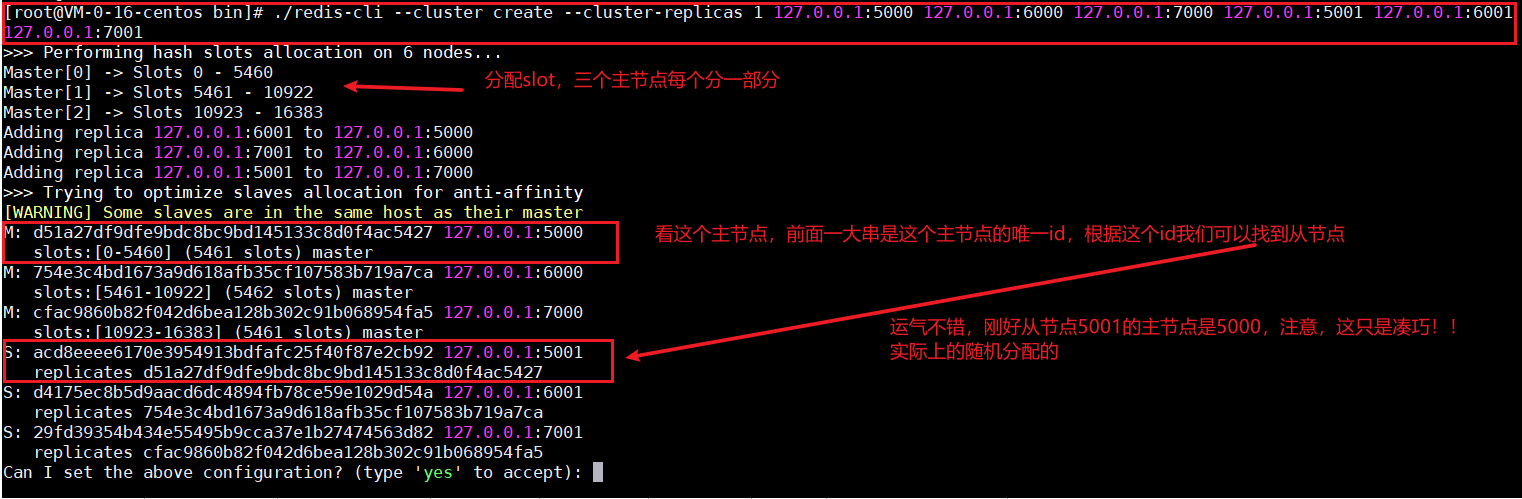
在bin目录下执行:./redis-cli --cluster create --cluster-replicas 1 127.0.0.1:5000 127.0.0.1:6000 127.0.0.1:7000 127.0.0.1:5001 127.0.0.1:6001 127.0.0.1:7001
命令说明,下图所示;
到这里,肯定有人想了,我要是有的主节点要有两个从节点呢?推荐看看这个老哥的博客,对这个命令解释得很详细

执行命令之后,输入"yes"表示保存这个集群,如果你对当前集群不满意,也可以重新执行一下上述命令
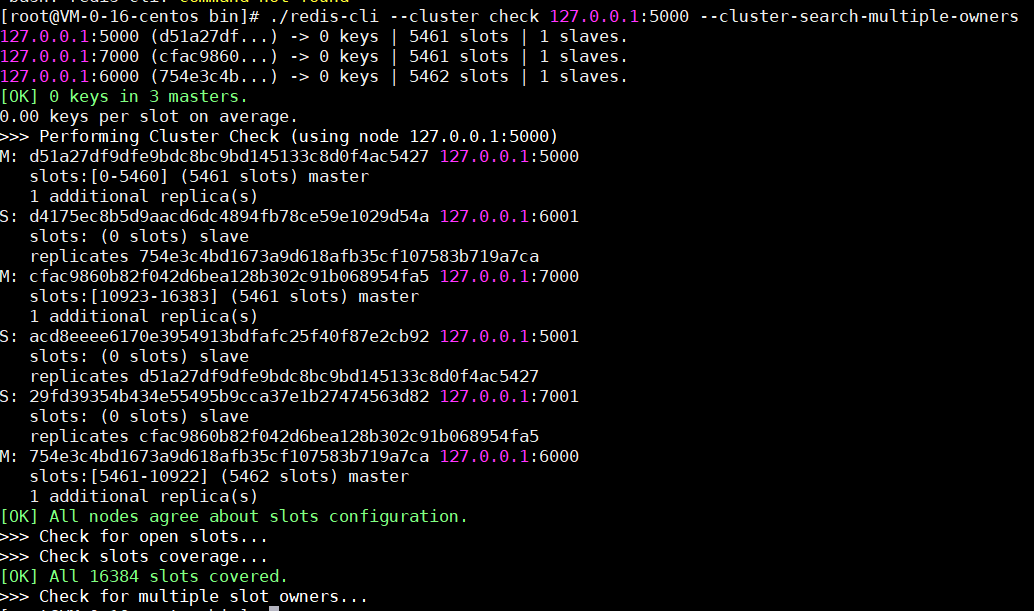
集群搭建完毕,我们只需要连接任意一个节点就能看看集群中节点的状态:./redis-cli -p 6000 cluster nodes

如果想看到集群中各个节点更详细的信息,也可以使用这个:./redis-cli --cluster check 127.0.0.1:5000 --cluster-search-multiple-owners
5.4 测试集群
我们关掉主节点5000,然后等几秒钟

然后再启动5000这个节点,我们发现5000节点成了5001的从节点了

我们随便连接一个节点放入数据:./redis-cli -p 5000 -c 注意要加上 -c 参数啊,这表示连接集群客户端

从集群中取数据

6. 总结
到这里redis的基础知识就说完了,最开始说的就只有一个节点的单机结构,弊端是容灾性差,这个节点坏了就就真的坏了,里面的数据还有可能丢失;
然后就说了解决容灾行的方案,即使用主从复制结构,但是主从当主节点坏了之后,虽然说数据肯定保存了一份在从节点那里,但是需要人为的去重新部署redis
再进一步就是说了哨兵机制,有个哨兵(当然,哨兵可以配置多个)一直盯着我们的主节点,当主节点没用了,就会自动的将从节点汇总选举出来一个作为主节点,继续向外提供服务
但是哨兵机制说到底还是单体架构,就会有单节点并发压力的问题,只有一个主节点无法抗住并发压力,而且所有数据都放在一台服务器中,随着redis用的时间越来越长,使得磁盘的空间也会很有压力
解决方案就是集群方式,可以有多个主节点共同组成一个集群向外界提供服务,数据大概就是均分成多份分别放在这些主节点中,这缓解了磁盘压力;而且每个主节点有多个从节点,且具备有主从复制+哨兵的作用,当主节点中数据有变化,就会同步到它对应的从节点中,提高了容灾性,然后主节点挂了,从节点还能顶上,提高了故障转移能力;
其实在集群创建完了之后,我们后续还可以向其中添加主节点和从节点的,这个就很容易了!
原文转载:http://www.shaoqun.com/a/521208.html
跨境电商:https://www.ikjzd.com/
kili:https://www.ikjzd.com/w/238
电霸:https://www.ikjzd.com/w/2597
redis5之前集群搭建需要ruby环境,redis5之后就不需要了,只用redis-cli就可以创建集群了,本文redis版本:5.0.41.前期回顾 前面说了redis的主从复制可以保证数据容灾,就是主节点坏了,从节点中也保存着完整数据,不会造成数据丢失的情况; 然后又说了哨兵模式(sentinel),这个是在主从复制的基础上增强了一下,当主节点坏了,从节点中就会选举出来一个当作主节点
tenso:tenso
卖家网:卖家网
口述:小姨子帮我猎艳被妻子暴打小姨子猎艳情敌:口述:小姨子帮我猎艳被妻子暴打小姨子猎艳情敌
分布式缓存系列之guava cache:分布式缓存系列之guava cache
各位卖家们,亚马逊黑五有感觉吗?:各位卖家们,亚马逊黑五有感觉吗?